Evaluating Automatic Generation of English Assessments
- Publication Date: 2021-02-09
| Execution Methods | The purpose of the cross-disciplinary project is to develop an AI-assisted test writing system which can satisfy the needs of English test writers. Researchers of Department of Computer Science and Engineering (CSE) focused on developing question generation models, question group generation models and distractor generation models, and incorporating these research results into a system. Data of user experience and feedback were collected and evaluated by researchers of Department of Foreign Languages and Literatures, including quality of test items, students’ answers to AI-generated questions, user perceptions and experiences. Question Group Generation: Question Generation (QG) task plays an important role for automating the preparation of educational reading comprehension assessment. While significant advancement on QG models were reported, the existing QG models are not ideal for educational applications. Having a question group is a common setting for reading comprehension assessment. However, the existing QG models are not designed to consider generating question group for educational applications. The goal of this project in CSE department is to generate multiple questions for a given article. We refer to such a setting as Question Group Generation (QGG). A workaround based on the existing QG models is to separately generate questions one after another to form a question group. However, an effective question group for assessment should consider context coverage, question intra question similarity, and question type diversity. Specifically, as suggested by on-site instructors, QGG should consider the following factors within a group. ● Intra-Group Similarity. An expected QGG with great utility should generate a question group containing questions with significant differences in syntax and semantics to increase the question variety and context coverage. ● Type Diversity. Furthermore, reading comprehension is the ability to process text and understand its meaning, which require various fundamental reading skills such as inferring the meaning of a word from context or identifying the main idea of a passage. Various question types are therefore designed for assessing corresponding skills. Thus, QGG should consider type diversity within a question group. In this project, we investigated the QGG issue by considering the above-mentioned attributes. We proposed a framework composed of two stages (as shown in the following figure). The first stage focused on generating multiple questions (as a candidate pool) based on pre-trained language models. We introduced the proposed QMST learning and NL learning techniques to address the challenge of generating similar questions. In the second stage, we took the generated questions with respect to the given context as input and selected a subset of the questions to form an optimal question group as final output based on genetic algorithm. Note that the optimal question group were formed by considering the type diversity, intra-group similarity, result quality, and context coverage. 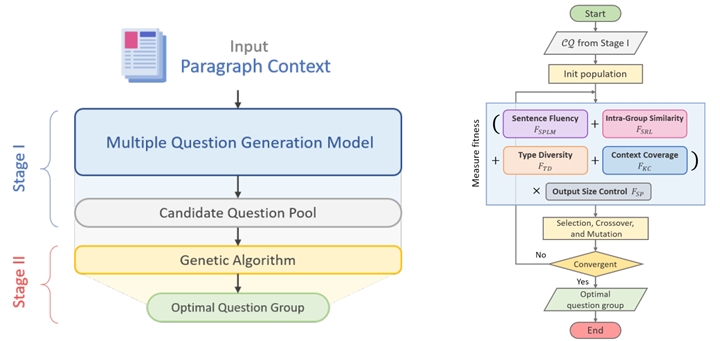 Data Collection:
|
| Performance Evaluation | For performance evaluation, we constructed a dataset (called QGG-RACE) from RACE for performance evaluation. The RACE dataset is an exam-type reading comprehension dataset, which was collected from real English tests for Taiwanese middle and high school students. Our QGG-RACE is a subset of RACE. There are 26640 (23971 for training, 1332 for dev, and 1337 for testing) passages and question groups. Each group consists of 2.69 questions. We evaluated our performance by (1) Group Quality Evaluation.: We employed the Bleu and Rouge-L metrics to measure the question quality with respect to gold labels. 2) Group Diversity Evaluation. To measure the group question diversity, we employed the Self-Bleu and Self-Rouge-L metrics. The results are summarized as follows. Data Collection and Analysis:
 |
| Conclusion & Suggestion |
For our AI-assisted test item writing system, please visit https://app.queratorai.com |
| Appendix |