人工智慧自動生成英文測驗之成效評估
- 刊登日期: 2021-02-09
| 執行方法及步驟 | 本計劃為外文系、資工系之跨領域計畫,共同開發合適應用英語教學場域之AI輔助命題系統。資工系專注於開發問題生成模型、題組生成模型、誘答選項生成模型,並將所有模型整合至Querator AI 輔助命題系統。外文系聚焦於資料蒐集,包含:蒐集考題建置資料集、學生作答記錄、教師對AI命題之感知問卷,以及AI輔助命題系統之使用經驗問卷、學生對AI命題之感知問卷。 模型開發 Question Group Generation: 問題生成於自動化閱讀理解測驗中扮演重要角色。隨著深度學習技術之成長,問題生成模型也有著長足之進步。也有許多卓越的研究成果與模型之使用已被提出。也因此觸發了本跨域合作之可能。計畫進行深度訪談以了解教師們的使用需求,我們發現生成問題題組(Question Group)反而是教師們覺得更實際的自動出題功能。然而,我們發現現有的QG生成模型,當初在設計考量時並非考慮一次生成一個題組; 現有QG模型主要考量一次生成一個問題題幹。針對題組,則呼叫同樣的模型多次來生成結果。也因此觸發了我們開發問題題組生成之動機。我們稱這樣的任務為QGG (Question Group Generation)。利用現有QG模型主要考量一次生成一個問題的做法忽略了問題題組中的問題彼此間應該要有所互補,涵蓋不同的難易度、不同的題目類型、不同的文章內容涵蓋區域。具體而言,根據與外文系老師們討論,QGG應當考量: ● Intra-Group Similarity (題組內部相似度). 一個有鑑別度且理想之問題題組應該包含語法差異、語意差異、內容涵蓋度差異。 ● Type Diversity (類型多樣性). 閱讀測驗主要鑑別學生理解文字與文意之差別。當中包含著許多不同的閱讀技能。比如說推斷一個字的字義,猜測一個字的字根,語義推理能力等等。因此QGG任務生成的同時也應該考量題型的多樣性。 在本年度的合作中,我們探討研究QGG任務(考量上述的兩個目標屬性)。我們提出一個框架其由兩個階段構成(如下圖所示)。第一個QGG生成階段為生成多個大量的問題候選 (a candidate pool)。我們設計不同的機器學習方法與負樣本學習技巧,並基於預訓練之語言模型來進行問句生成以確保其流暢性。第二個步驟則是利用組合最佳化(Combinational Optimization)的方式考量生成群組間之type diversity, intra-group similarity, result quality, 以及context coverage。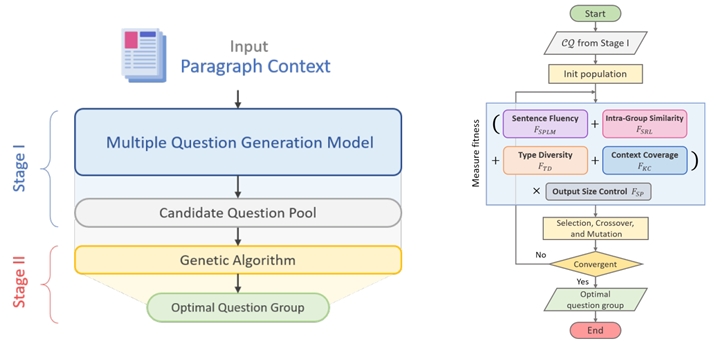 資料蒐集 從考古題、教科書、參考書中蒐集高品質之考題,建置模型之訓練資料集與測試資料集。
|
| 執行績效 | 模型開發: 對於性能評估,我們從 RACE 構建一個數據集(稱為 QGG-RACE)用於性能評估。 RACE數據集是一個考試類型的閱讀理解數據集,它是從國高中學生的真實英語考試中收集的。 我們的 QGG-RACE 是 RACE 的一個子集。 有 26640 個(23971 個用於訓練,1332 個用於開發,1337 個用於測試)段落和問題組。 每組由 2.69 個問題組成。 我們通過 (1) 群組質量評估來評估我們的表現。我們使用 Bleu 和 Rouge-L 指標來衡量與黃金標籤相關的問題質量。(2)群體多樣性評估:為了衡量群體問題的多樣性,我們採用了 Self-Bleu 和 Self-Rouge-L 指標。 結果總結如下: 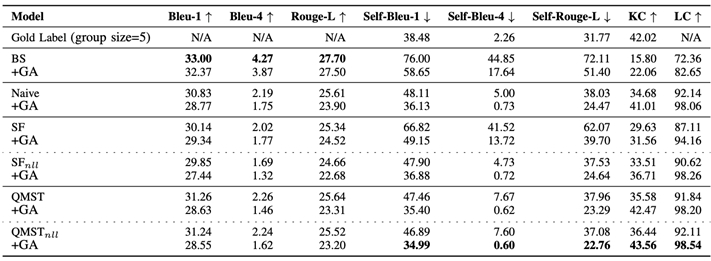 資料蒐集與初步分析:
|
| 結論與建議 |
QGG模型網址:https://demo.nlpnchu.org/ AI輔助命題系統網址:https://app.queratorai.com |
| 附件 |